
If you are looking for examples of effective knowledge mobilization, the health sector is a good place to start. Antismoking networks and organizations have become very effective at disseminating research findings in public messages that are accessible and memorable. The results of their efforts can be seen in the public policy changes that have expanded restrictions on smoking in workplaces and public spaces. While the work of these organizations provides insight into the knowledge mobilization process, Ross MacKenzie and Becky Freeman give us an interesting look at knowledge mobilization gone awry.
In the May 2010 issue of the Canadian Medical Association Journal, Ross MacKenzie and Becky Freeman shared the results of their investigation into a second-hand smoking statistic that was gradually embraced by both the antismoking advocacy groups and the public. The statistic in question stated that second-hand smoke is “23 times more toxic in a vehicle than in the home”. Ross and Becky were able to identify 19 articles that quote this statistic and found even more references to it in the media. With all of these citations over such a long period of time, what led Ross and Becky to question this statistic?
It turns out the devil really is in the details. While “conducting research for an Australian advocacy campaign to ban smoking in cars” Ross and Becky could find references to the statistic but could not find a “scientific source for this comparison”. No primary sources. In fact, a number of references offered no citation at all; the statistic was simply quoted as fact. How could this happen?
The first citation of this statistic is reportedly found in a 1998 newspaper article discussing legislation to ban smoking in cars. A politician was moved to introduce this legislation when she read it in a tobacco control advocacy group’s press-release, which cited a study in 1992. However, the 1992 study did not make the claim. It is unclear to me whether the statistic was misquoted or fabricated but what happened next is even more interesting. The “23 times more toxic” claim lay dormant for a few years and then resurfaced as a reference in a series of reports and articles published between 2003 and 2005. The claim again lay dormant for a few years and exploded in 2008 and 2009 in more reports and articles.
Ross and Becky include a network diagram in their article that describes the flow of the claim through organizational publications. In their visualization, each citation is listed in a box. Lines connecting the boxes describe the flow of citations from one report to another. Although the date of publication is included as a label in each box, it is not an organizing element. This may have served the purpose for Ross and Becky’s article but I think the timeline played a larger role in the evolution of myth to fact. Following are two visualizations that I have redesigned to include time as an organizing element.
In this first redesign of Ross and Becky’s diagram, the original reference (published in 1992) is at the centre of the visualization with annual rings radiating out and labeled with the works that perpetuate the false-claim. (Click on the image for a larger view)

In this visualization only the years with publications restating the false-claim have been labeled and shaded. The years between these citations are smaller, unshaded and unlabeled. It is easy to see in this visualization that there are periods of “quiet” where the false-claim is not included in organizational material. Unfortunately, the layout of this visualization discards the relationship between citations that were included in Ross and Becky’s diagram.
In this second redesign, the circular layout is exchanged for a modified hierarchical tree diagram. I have discarded the reference to the original publication (1992) and only included the first instances of the false-claim (1998). (Click on the image for a larger view)

In this visualization bubbles are labeled with the name of organizations or publications that reference the false-claim. Each organization is connected according to their citations. In addition to being an unusual data set to use in a tree diagram, additional modifications have been made. These modifications include attributing years of publication as level attributes and columns that organize the relationships between publications according to their distance from the original citation (primary, secondary sources etc.). The thickness of each year varies (expands and contracts) according to the number of publications or organizations that reference the false claim. Years where the false claim is not referenced are thin and unshaded whereas years where there are multiple references (for example 2009) are shaded and much thicker.
This visualization of data makes it possible to compare the position of articles and their “connectedness”. As bubbles move further to the right, they get “further away” from the original article (Rocky Mountain News) as a primary source. As bubbles move down the diagram, they recirculate the false claim and reintroduce it to peers and the public. For example, the Ontario Medical Association (OMA) Report revived the claim 6 years after the false claim was first published and appears to have been the most effective in the survival and persistence of the false-claim. Once included in the OMA report, the statistic was referenced in four other publications which further spawned four more citations.
The inclusion of the false-claim in a published form certainly increased its perceived credibility but in the intervening “quiet” years, researchers had the opportunity to question and challenge the statistic. Unchallenged, the false-claim emerged as a fact with its inclusion in additional publications and repeated citation by leaders and advocates. The publication of Ross and Becky’s work highlights the importance of knowledge mobilization and the extent to which it can have an impact on our lives. This is wonderful if the research is sound but serves as a warning that mistakes (whether innocent or malicious) do happen. It also highlights the researcher’s responsibility to continually challenge research findings regardless of how obvious or satisfying the results may be.



 timeanddate: h
timeanddate: h Opinion Lexicon:
Opinion Lexicon:
 Over the 5 days of CSSE (May 28 to June 1) there were 1,733 tweets to #Congress11 with most of the tweets being shared on Monday (447) and Tuesday (440). The top five contributors were @awatson8381 (95), @ColetteB (85), @Researchimpact (73), @Caitlinkealey (59) and @SSHRC_CRSH (50).
Over the 5 days of CSSE (May 28 to June 1) there were 1,733 tweets to #Congress11 with most of the tweets being shared on Monday (447) and Tuesday (440). The top five contributors were @awatson8381 (95), @ColetteB (85), @Researchimpact (73), @Caitlinkealey (59) and @SSHRC_CRSH (50).
 Juggling is fun to watch, a challenge to master and commonly used as a metaphor in project management. You might think jugglers are multi-taskers because they keep a group of objects moving in complex patterns, but take a closer look. How many of those objects (balls, bowling pins, flaming torches) do they hold? At any given time a juggler’s hand is only ever in contact with one object. As soon as that object is thrown into the air, the juggler’s hand (and attention) moves to the next object.
Juggling is fun to watch, a challenge to master and commonly used as a metaphor in project management. You might think jugglers are multi-taskers because they keep a group of objects moving in complex patterns, but take a closer look. How many of those objects (balls, bowling pins, flaming torches) do they hold? At any given time a juggler’s hand is only ever in contact with one object. As soon as that object is thrown into the air, the juggler’s hand (and attention) moves to the next object. Instead, jugglers are masters of serial-tasking. They place their full attention and focus on the patterns they are creating (the task) to impress the audience. By focusing on their task and seeing it through to the end, the juggler is better prepared to maintain their momentum and quickly regain it if they “drop the ball”. Like the juggler, when your time is protected so that you can direct your full attention and focus on a task to its completion, you are better equipped to account for all the details and quickly deal with the dropped balls. Where multi-tasking is a myth, switch-tasking is an exercise in frustration as your attention gets redirected with changing priorities and emergencies. It’s during the switching of tasks that details get overlooked and balls are dropped. Serial-tasking guards against this by focusing on a task to its completion before switching to the next high priority task.
Instead, jugglers are masters of serial-tasking. They place their full attention and focus on the patterns they are creating (the task) to impress the audience. By focusing on their task and seeing it through to the end, the juggler is better prepared to maintain their momentum and quickly regain it if they “drop the ball”. Like the juggler, when your time is protected so that you can direct your full attention and focus on a task to its completion, you are better equipped to account for all the details and quickly deal with the dropped balls. Where multi-tasking is a myth, switch-tasking is an exercise in frustration as your attention gets redirected with changing priorities and emergencies. It’s during the switching of tasks that details get overlooked and balls are dropped. Serial-tasking guards against this by focusing on a task to its completion before switching to the next high priority task.
{kind=link}
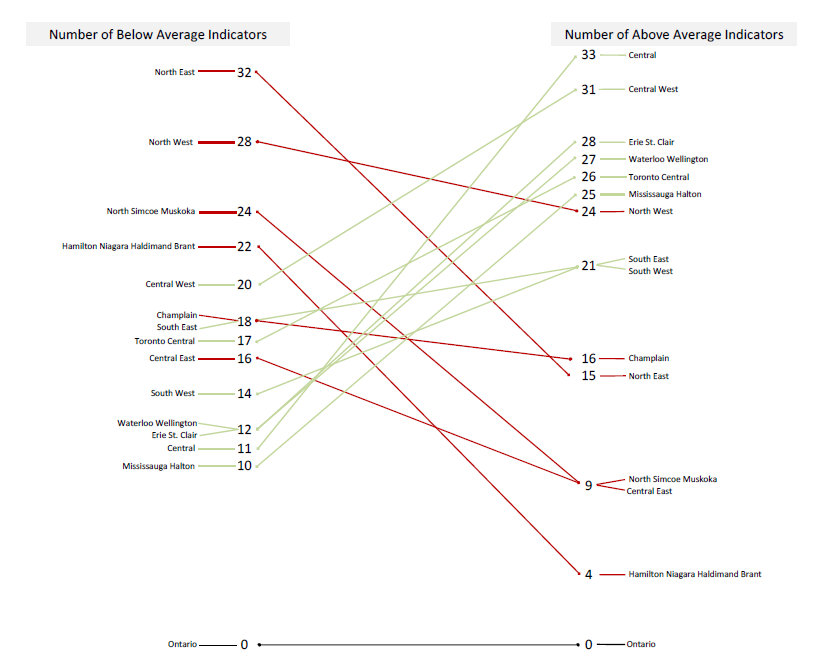{kind=link}
{kind=link}
{kind=link}